曲レコメンデーションの概念検証におけるメモリ測定
2025-05-13 23:30:25
原文: Song recommendations proof-of-concept memory measurements by Mark Seemann
測定の試みと、その結果。
これは関数型プログラミングによる設計の代替アプローチという連載記事の一部であり、前回の記事の直接的な続編です。 Impureimサンドイッチという概念検証の後に残った疑問は、「すべてのユーザー、曲、スクロブル(再生履歴)を事前に読み込む場合のメモリ要件はどれくらいか?」というものです。
推測することはできます(実際に以前行っています)が、測定する方が確実です。本記事では、その実験内容と結果について説明します。
テストプログラム
アプリケーションのメモリプロファイルを測定する機会はあまりないので、ネットで調べたところ、Jon Skeet氏によるこちらの回答を見つけました。信頼できる情報源なので、記載されている方法は適切だと判断しました。
ソースコードに新たなコマンドライン実行ファイルを追加し、以下をエントリーポイントとしました:
const int size = 100_000;
static async Task Main()
{
var before = GC.GetTotalMemory(true);
var (listeners, scrobbles) = await Populate();
var after = GC.GetTotalMemory(true);
var diff = after - before;
Console.WriteLine("Total memory: {0:N0}B.", diff);
GC.KeepAlive(listeners);
GC.KeepAlive(scrobbles);
}
listeners と scrobbles は、前回の記事で説明した通り、データを格納した2つの辞書です。これらが測定対象となるデータです。どちらも、以下のメソッドによって生成されます:
private static async Task<(
IReadOnlyDictionary<int, IReadOnlyCollection<User>>,
IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>>)> Populate()
{
var service = PopulateService();
var listeners = await service.CollectAllTopListeners();
var scrobbles = await service.CollectAllTopScrobbles();
return (listeners, scrobbles);
}
service 変数は、ランダムに生成されたデータを持つ FakeSongService オブジェクトです。CollectAllTopListeners と CollectAllTopScrobbles メソッドは前回と同じもので、メソッドが2つの辞書を返した後、service オブジェクトはスコープ外となり、ガベージコレクションの対象になります。 プログラムがメモリ負荷を測定する際には、2つの辞書のサイズのみを対象としており、service は含まれません。
ランダムなデータを生成するために、FsCheckのジェネレーターを再利用しました:
private static SongService PopulateService()
{
var users = RecommendationsProviderTests.Gen.UserName.Sample(size);
var songs = RecommendationsProviderTests.Gen.Song.Sample(size);
var scrobbleGen =
from user in Gen.Elements(users)
from song in Gen.Elements(songs)
from scrobbleCount in Gen.Choose(1, 10)
select (user, song, scrobbleCount);
var service = new FakeSongService();
foreach (var (user, song, scrobbleCount) in scrobbleGen.Sample(size))
service.Scrobble(user, song, scrobbleCount);
return service;
}
Gen<T> オブジェクトには Sample メソッドがあり、指定した数のランダムな値を取得できます。
コードを単純に保つために、size の値を曲数・ユーザー数・スクロブル数すべてに使いました。これによりスクロブル数が少なすぎる結果となっている可能性があります。これは後ほど再度議論が必要な点です。
測定結果
上記のプログラムを size にさまざまな値を設定して実行しました。100,000 から始め、1,000,000 まで 100,000 ずつ増加させ、その後は 500,000 ずつ増やしていきました。値が最大のときは、プログラムの実行に10分ほどかかりました。
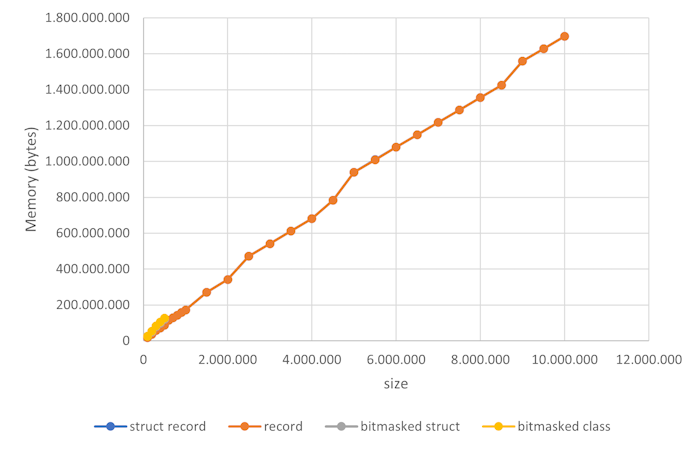
グラフからもわかるように、さまざまなデータ表現(詳細は後述)でプログラムを実行しました。4種類の異なるデータ系列がありますが、ペアごとにほぼ完全に重なっているため、違いは視覚的に確認できません。record と struct record の系列は全く同じに見え、bitmasked class と bitmasked struct の系列も同様で、これらは size が 500,000 までしか表示されていません。
4,500,000 から 5,000,000、そして 8,500,000 から 9,000,000 への間で小さなジャンプはあるものの、全体としては直線的な関係が見て取れます。つまり、データサイズに対して線形にスケールするという結論が妥当であるようです。
サイズあたりのバイト数はほぼ一定で、平均して178バイトです。これは、以前のメモリサイズの推定値と比べてどうでしょうか? その時は、曲とスクロブルがそれぞれ8バイト、ユーザーが32バイト未満と見積もっていました。このシミュレーションでは、1ユニットあたり曲1件、ユーザー1人、スクロブル1件を生成するため、1ユニットあたりの平均メモリコストは 8 + 8 + 32 = 48 バイト程度と予想されます。そこに辞書のオーバーヘッドが加わると見ていました。
実測値が178バイトということは、130バイトがオーバーヘッドになります。正直、これは予想よりも多いです。辞書はおそらくキーの配列を保持し、ハッシュ値ごとにバケツを持っているのでしょう。Dictionary 以外のデータ構造を使えば、異なるオーバーヘッドになったかもしれません。あるいは、.NETのメモリモデルを実はきちんと理解できていないのかもしれません。
次に、単一の size パラメータを3つに分けて、ユーザー数・曲数・スクロブル数をそれぞれ個別に制御しました。ユーザー数と曲数を1000万に設定し、スクロブル数を増加させながらシミュレーションを実行しました。
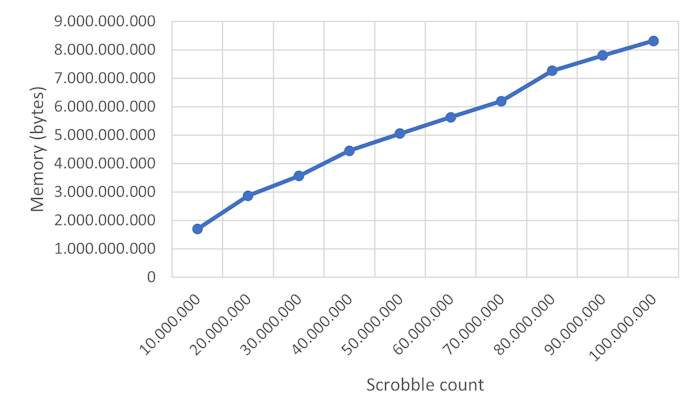
この関係も依然として線形に見えます。スクロブルが1億件、ユーザーと曲がそれぞれ1000万件ある場合、このシミュレーションでは8.3GBのメモリを使用しました。
以前の見積もりでは1.2GB程度と予想していたため、実測値はその約7倍です。1桁違いとまではいきませんが、それに近い差があります。
リアリズム
これらの測定結果はどれほど有用でしょうか?この実験のパラメータは現実的なのでしょうか? 多くの音楽ストリーミングサービスは、約1億曲のカタログを有していると報告しています。これは、ここで測定した値の10倍です。そうしたサービスは、ユーザー数も1000万よりずっと多い可能性があります。 しかし、このアーキテクチャ案(すべてのデータをメモリに保持する)が実現可能かどうかを左右するのは、ユーザーがどれだけ多くスクロブル(曲再生履歴)を持つか、そして1曲を何回再生するか、です。
仮に、スクロブル1件が8バイトしか必要ないと単純に信じたとしても、100件のスクロブルが800バイトを消費するとは限りません。繰り返し再生の有無が影響します。 スクロブルのモデリング方法を思い出してください:
public sealed record Scrobble(Song Song, int ScrobbleCount);
もしユーザーが同じ曲を10回再生したなら、Scrobble オブジェクトを10個作る必要はありません。1つのオブジェクトで ScrobbleCount を 10 に設定すれば済みます。
ユーザーのスクロブルを保存するために必要なメモリは、平均的な再生パターンに依存します。 数百万のユーザーがいても、それぞれが比較的少数の曲しか聴かないのであれば、スクロブルをメモリに保持することも可能かもしれません。 一方で、もしユーザーが各曲を一度しか聴かないのであれば、おそらくメモリには収まりません。
それでも、メモリに収まるか収まらないかのギリギリのラインに近づいているのは間違いありません。 では、このアイデアはもう破綻していると見なして、諦めるべきでしょうか?
この連載記事全体の目的は、Impureimサンドイッチ パターンに対する 代替手法 を示すことなので、最終的にはその通りに進みます。
ですが、まだその段階ではありません。
シャーディング(分割)
アプリケーションによっては、本当にグローバルな規模で運用されることがあります。そうした場合、すべてをメモリに載せるという手法は “Webスケール” ではないかもしれません。
それでも、複数の国際的企業が地理的領域を独立した単位として扱っているのを私は何度も見てきました。 法的な理由があるなど、技術とは無関係なビジネス上の都合によることもあります。
プログラマーとしては、曲レコメンデーションのサービスはグローバルであるべきだと考えるかもしれません。 なぜなら、データ量が多ければ多いほど、より正確な結果が得られるからです。
しかし、ビジネスオーナーはそうは考えないかもしれません。 地域ごとの音楽嗜好が “市場の境界” を越えて混ざることで、結果的に顧客が離れてしまうことを懸念するかもしれません。
仮に、あなたがその懸念が無意味だと技術的に証明できたとしても、ビジネス側から明確な指示が出るかもしれません。 例えば、「東南アジアのスクロブルは北米で使ってはならない」あるいはその逆、というように。
こうしたビジネス上または法的な制約が既に存在するかどうかは、調査してみる価値があります。 もし存在するのであれば、データをシャーディングして、それぞれをメモリに収めることが可能かもしれません。
あなたはもしかすると「悪いアイデアをなんとか正当化しようとしている」と思うかもしれませんが、それが私の目的ではありません。 こうした話題を取り上げるのは、私の経験上、多くのプログラマーがこのような視点を考慮に入れていないからです。 問題のより広い文脈を理解すれば、それまで見落としていた解決策が見えてくるかもしれません。
しかし、もし将来的にビジネス上の制約が変化したら?そのときに対応できるようにしておくべきでは?
それについては、イエスでもありノーでもあります。 そのような変更がアーキテクチャに与える影響をあらかじめ考慮するべきです。そして、そのメリットとデメリットを他の関係者と議論するべきです。
そもそも Impureimサンドイッチパターンを検討する理由は、それが シンプル であり、実装や保守がしやすいからです。 他の選択肢は「よりスケーラブル」かもしれませんが、その分実装のリスクが高まります。 こうした決定は、他の関係者を巻き込んで行うべきです。
曲のデータ表現
上記の最初のグラフでは、以下の4種類のデータ系列を示しています:
- struct record
- record
- bitmasked struct
- bitmasked class
これらは、データ、具体的には「曲」をモデル化する4つの異なる方法を測定しています。
当初、私は曲を record としてモデル化しました:
public sealed record Song(int Id, bool IsVerifiedArtist, byte Rating);
次に、型の中身がすべて値型で構成されていたため、上記の record を record struct に変更する方が適しているのではないかと考えました:
public record struct Song(int Id, bool IsVerifiedArtist, byte Rating);
しかし、実際には目に見える差はありませんでした。グラフ上でも、2つのデータ系列は非常に近接しており、視覚的に区別がつかないほどです。
次に考えたのは、int、bool、byte をそれぞれ保持する代わりに、1つのビットマスクを用いて3つの値すべてを表現することでした。
そもそもデータ型の選定は推測に基づいて行っていたものです。たとえば、Rating(評価)は5段階や10段階スケールである可能性が高いのに、私は byte を使っていました。これは、型の持つ範囲の96%を使っていないということになります。 その余ったビットを使って IsVerifiedArtist を bool ではなくビットで表現できるのではないか、という発想です。
さらに踏み込むと、Id を int としてモデル化したことは、曲のユニーク数が最大で 4,294,967,295 曲まで対応できることを意味します。これは43億曲であり、一般的に言われる1億曲と比べて1桁多い値です。 実際には、多くのシステムが ID に int を使っているのは、それがCLS準拠であり、uint はそうでないからです。つまり、int を使っていても、実際に使っているのは正の数だけであることがほとんどです。 そのため、使用されていない16ビット分に他の情報を詰め込めるかもしれません。そこで登場するのが bitmasked song です:
public readonly struct Song
{
private const uint idMask =
0b0000_0111_1111_1111_1111_1111_1111_1111;
private const uint isVerifiedArtistMask =
0b1000_0000_0000_0000_0000_0000_0000_0000;
private const uint ratingMask =
0b0111_1000_0000_0000_0000_0000_0000_0000;
private readonly uint bits;
public Song(int id, bool isVerifiedArtist, byte rating)
{
var idBits = (uint)id & idMask;
var isVerifiedArtistBits = isVerifiedArtist ? isVerifiedArtistMask : 0u;
var ratingBits = ((uint)rating << 27) & ratingMask;
bits = idBits | isVerifiedArtistBits | ratingBits;
}
public int Id => (int)(bits & idMask);
public bool IsVerifiedArtist =>
(bits & isVerifiedArtistMask) == isVerifiedArtistMask;
public byte Rating => (byte)((bits & ratingMask) >> 27);
}
この表現では、下位27ビットを ID に割り当て、範囲は 0 〜 134,217,727(約1億3千万)としています。最上位1ビットを IsVerifiedArtist に使用し、残りの4ビットを Rating に使用しています。
このデータ構造は単一の uint を保持しており、しかも struct として定義されているため、オーバーヘッドは最小になるはずだと考えました。
ですが、結果としてそうはなりませんでした。実験結果を見ると、この表現は より多くのメモリ を消費していました。
念のため、bitmasked Song を class に変えてもみましたが、視覚的な差異は見られませんでした。
もし、bitmasked 系のデータ系列が最大で50万(size = 500,000)までしかグラフにない理由が気になっているなら、それはこの変更によって実験の実行速度が極端に遅くなったからです。 size を50万に設定した場合でも、実行に12〜24時間かかりました。
このスローダウンは、データ表現そのものよりも、FsCheckベースのデータジェネレーターに加えた変更によるものである可能性が高いと考えています:
let songParams = gen {
let maxId = 0b0111_1111_1111_1111_1111_1111_1111
let! songId = Gen.choose (1, maxId)
let! isVerified = ArbMap.generate ArbMap.defaults
let! rating = Gen.choose (0, 10) |> Gen.map byte
return songId, isVerified, rating }
[<CompiledName "Song">]
let song = gen {
let! (id, isVerifiedArtist, rating) = songParams
return Song (id, isVerifiedArtist, rating) }
なぜ bitmasked 表現の方がメモリを多く消費するのか、私には説明できません。 ですが、どこかで何かを間違えてしまっているのではないかという不安が、徐々に強くなってきています。 もし誤りを見つけた方がいれば、ぜひコメントで教えてください。
その他のデータ表現
データ全体を巨大な行列として表現するという案も考えました。たとえば、行をユーザー、列を曲とし、それぞれの要素にそのユーザーが特定の曲を再生した回数を格納するという方式です:
| User | Song 1 | Song 2 | Song 3 | … |
|---|---|---|---|---|
| 123 | 0 | 0 | 4 | … |
| 456 | 2 | 0 | 4 | … |
| … |
ある程度のユーザーは、1つの曲を255回以上聴くかもしれませんが、65,535回(ushort の上限)を超えることはおそらくありません。 そのため、各再生回数を ushort で保持できると仮定します。 しかし、必要となるのは「ユーザー数 × 曲数」の値なので、仮に曲数が1億、ユーザー数が1000万とすると、必要なメモリは2ペタバイトになります。これは現実的ではありません。
一方で、大半の要素は 0 になると考えられるので、隣接リストのような表現を用いることも考えられます。 しかしそれは、実質的に IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> と同じ構造です。つまり、元の場所に戻ってきたことになります。
結論
この記事では、すべてのスクロブルデータをメモリ上に保持するという前提でのメモリ要件について、私が行った測定結果を報告しました。 どこかでミスをしている可能性もありますが、それでもなお、この 曲レコメンデーション のシナリオが Impureimサンドイッチパターンの限界近くにあることは確かだと考えています。
それで構いません。私の関心は、ソリューションの限界を理解することにあります。
ただし、Impureimサンドイッチパターンが使えなくなるまでには、どれほど大量のデータが必要かという点には注目すべきだと思います。
私がこのパターンを説明すると、最もよく返ってくる反応は「スケーラビリティがない」というものです。そして、本記事が検討したように、それは確かに事実です。 ですが、あなたが思っているよりも遥かにスケーラブル であるということもまた事実です。 あなたのシステムに何十億ものエンティティがあったとしても、それが数ギガバイトに収まる可能性はあるのです。 Impureimサンドイッチパターンを、メモリ面の検証もせずに「使えない」と決めつけないでください。 あなたの直感は、おそらくこの件に関しては間違っています。
この連載の締めくくりとして、Impureimサンドイッチパターンをより関数型寄りの言語でどのように記述するかをお見せします。
次回: F#版 Impureim Sandwichにした曲レコメンデーション