Haskellによる画像アーキビスト
2025-04-14 17:00:25
原文: Picture archivist in Haskell by Mark Seemann
Haskellで関数型アーキテクチャを実装する方法を示す包括的なコード例
この記事では、前の記事で解説した画像アーキビストのアーキテクチャを、実際にHaskellでどのように実装するかを解説します。具体的には、撮影日のメタデータに基づいて、複数の画像ファイルを適切なディレクトリに移動させるタスクを扱います。そのアーキテクチャの基本的な考え方は、ディスク上のディレクトリ構造をメモリ内の木構造としてロードし、そのツリーを操作した後、操作後のツリーを使って目的の処理を実行するというものです。
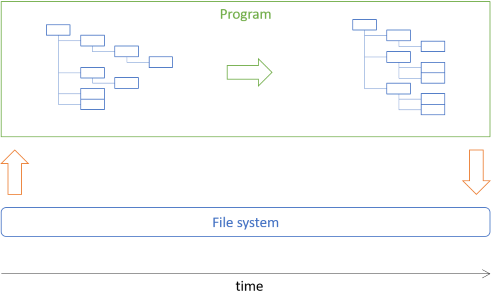
プログラムの大部分は、不変であるツリーデータを操作することになります。
木構造
まず、Rose木(分岐数が一定でない多分木)を定義します。
data Tree a b = Node a [Tree a b] | Leaf b deriving (Eq, Show, Read)
このTreeに関するコードは、画像の移動といった特定のアプリケーションに依存しないため、再利用可能なライブラリとしてまとめることも可能です。これらの関数については、網羅的なテストスイートを作成することもできますが、この記事では省略します。
ここで重要なのは、この木構造が内部ノードとリーフノードを明確に区別している点です。これは、ディレクトリ名(内部ノード)を追跡すると同時に、リーフにのみ追加のデータを持たせたいという要件があるためです。内部ノードに意味のあるデータを追加することはできません。この点は、記事の後半で詳しく説明します。
Rose木のカタモーフィズムは、このfoldTree関数で表されます。
foldTree :: (a -> [c] -> c) -> (b -> c) -> Tree a b -> c
foldTree _ fl (Leaf x) = fl x
foldTree fn fl (Node x xs) = fn x $ foldTree fn fl <$> xs
カタモーフィズムには、cataやtreeといった名前をつけることもありますが、この記事ではData.Treeライブラリに触発され、foldTreeと名付けることにしました。
この記事では、(1つの例外を除き)ツリーの機能は、直接的または推移的にfoldTreeを使って実装されています。
ツリーのフィルタリング
ツリーの内容をフィルタリングできると便利な場合があります。たとえば、画像アーキビストプログラムでは、メタデータが有効な画像ファイルのみを移動します。つまり、画像ファイルでないファイルや、有効なメタデータを持たない画像ファイルは除外する必要があります。
ここで、Maybe型のリーフを持つツリーから、Nothing値を取り除く関数があると便利です。これは、Data.MaybeモジュールのcatMaybes関数と似ているため、catMaybeTreeと名付けました。
catMaybeTree :: Tree a (Maybe b) -> Maybe (Tree a b)
catMaybeTree = foldTree (\x -> Just . Node x . catMaybes) (fmap Leaf)
この関数の型を見て、驚かれるかもしれません。なぜ、単にTreeを返すのではなく、Maybe Treeを返すのでしょうか? また、与えられた型が納得できたとしても、これは単にsequence関数と同じではないのでしょうか?
catMaybesはリストを返しますが、リストは空にできるため、これで問題ありません。一方、このTree型は空にすることができません。catMaybeTreeの目的が、すべてのNothing値を取り除くことだとすると、Leaf Nothingからどのようにツリーを返せばよいのでしょうか?
リーフに入れる値がないため、Leafを返すことはできません。同様に、ノードに入れる値がないため、Nodeを返すこともできません。
したがって、このエッジケースを処理するには、Nothingを返す必要があります。
Prelude Tree> catMaybeTree $ Leaf Nothing
Nothing
では、これはsequenceと同じなのでしょうか? そうではありません。sequenceは、次のリストの例が示すように、すべてのデータをショートカットしてしまうからです。
Prelude> sequence [Just 42, Nothing, Just 2112]
Nothing
一方、catMaybesの動作は次のようになります。
Prelude Data.Maybe> catMaybes [Just 42, Nothing, Just 2112]
[42,2112]
TreeのTraversableインスタンスはまだ見ていませんが、同様の動作をします。
Prelude Tree> sequence $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)]
Nothing
それに対し、catMaybeTree関数は、フィルタリングされたツリーを返します。
Prelude Tree> catMaybeTree $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)]
Just (Node "Foo" [Leaf 42,Leaf 2112])
結果のツリーはJustでラップされていますが、リーフにはラップされていない値が含まれています。
インスタンス
Rose木のカタモーフィズムに関する記事では、Bifunctor、Bifoldable、およびBitraversableのインスタンスを追加する方法についてすでに説明しました。そのため、ここでは簡単に触れるにとどめます。詳細については、該当の記事を参照してください。また、この記事に付随するコードには、これらのインスタンスに関連するさまざまな法則を検証するQuickCheckプロパティも含まれています。ここでは、インスタンスをリストするだけにして、詳細な説明は省略します。
instance Bifunctor Tree where
bimap f s = foldTree (Node . f) (Leaf . s)
instance Bifoldable Tree where
bifoldMap f = foldTree (\x xs -> f x <> mconcat xs)
instance Bitraversable Tree where
bitraverse f s =
foldTree (\x xs -> Node <$> f x <*> sequenceA xs) (fmap Leaf . s)
instance Functor (Tree a) where
fmap = second
instance Foldable (Tree a) where
foldMap = bifoldMap mempty
instance Traversable (Tree a) where
sequenceA = bisequenceA . first pure
画像アーキビストプログラムは、これらのすべてを明示的に必要とするわけではありませんが、間接的には必要になります。
画像の移動
ここまでで示されたコードは、画像ファイルに固有の機能を含んでいないため、汎用的な再利用可能ライブラリに含めることができます。しかし、この記事の残りのコードは、このプログラムに固有のものとなります。ドメインモデルのコードを別のモジュールに配置し、いくつかの機能をインポートします。
module Archive where
import Data.Time
import Text.Printf
import System.FilePath
import qualified Data.Map.Strict as Map
import Tree
Treeもインポートされたモジュールの1つであることに注目してください。
後で、ファイルシステムからツリーをロードする方法を見ていきますが、今のところは、そのようなツリーがすでに存在するものとします。
このプログラムの主要なロジックは、ソースツリーに基づいて、移動先のツリーを作成することです。ツリーのリーフは、ファイルパスに加えて追加の情報を持つ必要があるため、その情報を保持するための特定の型を導入します。
data PhotoFile =
PhotoFile { photoFileName :: FilePath, takenOn :: LocalTime }
deriving (Eq, Show, Read)
PhotoFileは、画像ファイルのファイルパスだけでなく、画像が撮影された日付も含みます。この日付は、ファイルのメタデータから抽出できますが、これは純粋でない操作であるため、プログラムの開始時にこの処理を行います。これについては後ほど説明します。
PhotoFile型のリーフを持つソースツリーが与えられたとき、プログラムはファイルの移動先のツリーを生成する必要があります。
moveTo :: (Foldable t, Ord a, PrintfType a) => a -> t PhotoFile -> Tree a FilePath
moveTo destination =
Node destination . Map.foldrWithKey addDir [] . foldr groupByDir Map.empty
where
dirNameOf (LocalTime d _) =
let (y, m, _) = toGregorian d in printf "%d-%02d" y m
groupByDir (PhotoFile fileName t) =
Map.insertWith (++) (dirNameOf t) [fileName]
addDir name files dirs = Node name (Leaf <$> files) : dirs
このmoveTo関数は、少し複雑に見えるかもしれませんが、実際には次の3つのステップで構成されています。
- 移動先のフォルダのマップを作成します (
foldr groupByDir Map.empty)。 - マップからブランチのリストを作成します (
Map.foldrWithKey addDir [])。 - リストからツリーを作成します (
Node destination)。
Haskellの関数が.演算子で合成される場合、右から左に読んでいく必要があることを思い出してください。
この関数は、Foldable型のデータコンテナであれば動作することに注意してください。したがって、ツリーだけでなく、リストや他のデータ構造でも動作します。
moveTo関数は、入力データをマップに畳み込むことから始まります。このマップは、dirNameOf関数によってフォーマットされたディレクトリ名をキーとして持ちます。dirNameOf関数は、LocalTime型を入力として受け取り、YYYY-MM形式の文字列にフォーマットします。たとえば、2018年12月20日は"2018-12"となります。
マッピングのステップ全体で、PhotoFileの値はMap a [FilePath]型のマップにグループ化されます。2014年4月に撮影されたすべての画像ファイルは"2014-04"キーを持つリストに追加され、2011年7月に撮影されたすべての画像ファイルは"2011-07"キーを持つリストに追加されるというように処理されます。
次のステップで、moveTo関数はマップをツリーのリストに変換します。これは、destinationディレクトリのブランチ(つまりサブディレクトリ)になります。移動先のツリーに必要な構造のため、これは浅いブランチのリストとなります。各ノードはリーフのみを含みます。

残りのステップは、このブランチのリストをdestinationノードに追加することだけです。
これは純粋関数であるため、ユニットテストが容易です。いくつかの入力データを作成し、関数を呼び出すだけです。
"Move to destination" ~: do
(source, destination, expected) <-
[
( Leaf $ PhotoFile "1" $ lt 2018 11 9 11 47 17
, "D"
, Node "D" [Node "2018-11" [Leaf "1"]])
,
( Node "S" [
Leaf $ PhotoFile "4" $ lt 1972 6 6 16 15 00]
, "D"
, Node "D" [Node "1972-06" [Leaf "4"]])
,
( Node "S" [
Leaf $ PhotoFile "L" $ lt 2002 10 12 17 16 15,
Leaf $ PhotoFile "J" $ lt 2007 4 21 17 18 19]
, "D"
, Node "D" [Node "2002-10" [Leaf "L"], Node "2007-04" [Leaf "J"]])
,
( Node "1" [
Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15,
Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15,
Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19]
, "2"
, Node "2" [
Node "2010-01" [Leaf "a", Leaf "c"],
Node "2010-03" [Leaf "b"]])
,
( Node "foo" [
Node "bar" [
Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15,
Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15,
Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19],
Node "baz" [
Leaf $ PhotoFile "d" $ lt 2010 3 1 2 3 4,
Leaf $ PhotoFile "e" $ lt 2011 3 4 3 2 1
]]
, "qux"
, Node "qux" [
Node "2010-01" [Leaf "a", Leaf "c"],
Node "2010-03" [Leaf "b", Leaf "d"],
Node "2011-03" [Leaf "e"]])
]
let actual = moveTo destination source
return $ expected ~=? actual
これはインライン化された パラメータ化されたHUnitテストです。大きなユニットテストのように見えますが、テストのフォーマットに関するヒューリスティックに従っています。式は3つしかありませんが、arrange式が大きいのは、テストケースのリストを作成するためです。
各テストケースは、sourceツリー、destinationディレクトリ名、およびexpected結果の3つの要素からなる組です。テストデータコードをよりコンパクトにするために、テスト固有の次のヘルパー関数を使用します。
lt y mth d h m s = LocalTime (fromGregorian y mth d) (TimeOfDay h m s)
各テストケースについて、テストは`destinationディレクトリ名とsourceツリーを指定してmoveTo関数を呼び出します。次に、expected値がactual値と等しいことをアサートします。
移動処理の計算
純粋な処理が1つ残っています。moveTo関数を呼び出した結果は、目的の構造を持つツリーです。ただし、実際にファイルを移動するには、各ファイルについて、移動元のパスと移動先のパスの両方を追跡する必要があります。これを明確にするために、この目的のために型を定義します。
data Move =
Move { sourcePath :: FilePath, destinationPath :: FilePath }
deriving (Eq, Show, Read)
Moveは単なるデータ構造です。これを、オブジェクトの(おそらくポリモーフィックな)メソッドである典型的なオブジェクト指向設計と比較してみてください。関数型プログラミングでは、意図をデータ構造としてモデル化することがよくあります。意図がデータである限り、それらを簡単に操作できます。処理が終わったら、そのデータ構造上でインタープリターを実行して、やりたいことを実行できます。
moveTo関数のユニットテストケースでは、ファイル名が"L"、"J"、"a"などのローカルファイル名であることが示されています。これは、関数が実際に特定のFilePath値を操作しないため、テストをできるだけコンパクトにするためだけの措置でした。
実際には、ファイル名はもっと長く、"C:\foo\bar\a.jpg"のようなフルパスを含むこともあります。
各リーフがフルパスを持つツリーでmoveToを呼び出すと、出力ツリーは目的の移動先木構造を持ちますが、リーフには各移動元ファイルへのフルパスがまだ含まれます。つまり、各ファイルに対してMoveを計算できます。
calculateMoves :: Tree FilePath FilePath -> Tree FilePath Move
calculateMoves = imp ""
where imp path (Leaf x) = Leaf $ Move x $ replaceDirectory x path
imp path (Node x xs) = Node (path </> x) $ imp (path </> x) <$> xs
この関数は、Tree FilePath FilePathを入力として受け取ります。これは、moveToの出力と互換性があります。そして、Tree FilePath Move、つまり、リーフがMove値であるツリーを返します。
公平を期すために言っておくと、ツリーを返すのは少しやりすぎかもしれません。 [Move](移動のリスト)でも十分に役立ちますが、この記事では、関数型アーキテクチャでコードを作成する方法を説明しようとしています。概要の記事では、Rose木を使用してファイルシステムをモデル化する方法を説明しました。その点を強調するために、もう少しの間、そのモデルに固執します。
以前、foldTree関数を使用して目的のTree機能を実装できると書きましたが、これは単純化しすぎた表現でした。foldTreeを使用してcalculateMovesの機能を実装する方法は、私にはわかりません。ただし、明示的なパターンマッチングと単純な再帰を使用すると、実装できます。
imp関数は、ツリーを再帰的に処理しながら、(</>パス結合子を使用して)ファイルパスを構築します。すべてのLeafノードは、リーフノードの現在のFilePath値をsourcePathとして、またpathを使用して目的のdestinationPathを把握することにより、Move値に変換されます。
このコードも、ユニットテストが容易です。
"Calculate moves" ~: do
(tree, expected) <-
[
(Leaf "1", Leaf $ Move "1" "1"),
(Node "a" [Leaf "1"], Node "a" [Leaf $ Move "1" $ "a" </> "1"]),
(Node "a" [Leaf "1", Leaf "2"], Node "a" [
Leaf $ Move "1" $ "a" </> "1",
Leaf $ Move "2" $ "a" </> "2"]),
(Node "a" [Node "b" [Leaf "1", Leaf "2"], Node "c" [Leaf "3"]],
Node "a" [
Node ("a" </> "b") [
Leaf $ Move "1" $ "a" </> "b" </> "1",
Leaf $ Move "2" $ "a" </> "b" </> "2"],
Node ("a" </> "c") [
Leaf $ Move "3" $ "a" </> "c" </> "3"]])
]
let actual = calculateMoves tree
return $ expected ~=? actual
このパラメータ化されたテストのテストケースは、入力treeとexpectedツリーのペアです。各テストケースについて、テストはtreeを使用してcalculateMoves関数を呼び出し、actualツリーがexpectedツリーと等しいことをアサートします。
これで、目的の機能を実装するために必要なすべての純粋なコードが揃いました。あとは、ディスクからツリーをロードし、移動先のツリーをディスクに書き込み、そしてそれらすべてを構成するコードを記述するだけです。
ディスクからツリーをロードする
この記事の残りのコードは、純粋ではありません。専用のモジュールに配置することもできますが、このプログラムに必要なのは、3つの関数と少しの構成コードだけなので、すべてをMainモジュールに配置することもできます。私はそうしました。
ディスクからツリーをロードするには、ツリー全体をロードするルートディレクトリが必要です。ディレクトリパスが与えられたら、次のような再帰関数を使用してツリーを読み取ります。
readTree :: FilePath -> IO (Tree FilePath FilePath)
readTree path = do
isFile <- doesFileExist path
if isFile
then return $ Leaf path
else do
dirsAndfiles <- listDirectory path
let paths = fmap (path </>) dirsAndfiles
branches <- traverse readTree paths
return $ Node path branches
この再帰関数は、最初にpathがファイルであるかディレクトリであるかをチェックします。ファイルの場合、そのFilePathを使用して新しいLeafを作成します。
pathがファイルでない場合、それはディレクトリです。その場合、listDirectoryを使用して、そのディレクトリ内のすべてのディレクトリとファイルを列挙します。これらはローカル名のみであるため、完全なパスを作成するためにそれらにpathをプレフィックスとして付け、次にそれらのすべてのディレクトリエンントリーを再帰的に処理します。これにより、現在のノードのすべてのbranchesが生成されます。最後に、pathとbranchesを使用して新しいNodeを返します。
メタデータをロードする
readTree関数は、FilePath型のリーフを持つツリーのみを生成しますが、プログラムに必要なのはPhotoFile型のリーフを持つツリーです。したがって、各ファイルからExifメタデータを読み取り、date-takenデータでツリーを拡張する必要があります。
このコードベースでは、このためにhsexifライブラリを使用しました。これにより、次のような純粋でない操作を記述できます。
readPhoto :: FilePath -> IO (Maybe PhotoFile)
readPhoto path = do
exifData <- parseFileExif path
let dateTaken = either (const Nothing) Just exifData >>= getDateTimeOriginal
return $ PhotoFile path <$> dateTaken
この操作は、さまざまな理由で失敗する可能性があります。
- ファイルが存在しない。
- ファイルは存在するが、メタデータがない。
- ファイルにはメタデータがあるが、date-takenメタデータがない。
- date-takenメタデータ文字列の形式が正しくない。
プログラムは、date-takenメタデータを抽出できないすべてのファイルをスキップするため、readPhotoはparseFileExifによって返されたEither値をMaybeに変換し、getDateTimeOriginalで結果を連結します。
readPhotoでTree FilePath FilePathをtraverseすると、Tree FilePath (Maybe PhotoFile)が得られます。ここで、catMaybeTreeが必要になります。これについては、すぐ後で説明します。
ツリーをディスクに書き込む
上記のcalculateMoves関数は、Tree FilePath Moveを作成します。記述する必要がある最後の純粋でないコードは、そのようなツリーを走査し、各Moveを実行する操作です。
applyMoves :: Foldable t => t Move -> IO ()
applyMoves = traverse_ move
where
move m = copy m >> compareFiles m >>= deleteSource
copy (Move s d) = do
createDirectoryIfMissing True $ takeDirectory d
copyFileWithMetadata s d
putStrLn $ "Copied to " ++ show d
compareFiles m@(Move s d) = do
sourceBytes <- B.readFile s
destinationBytes <- B.readFile d
return $ if sourceBytes == destinationBytes then Just m else Nothing
deleteSource Nothing = return ()
deleteSource (Just (Move s _)) = removeFile s
上で述べたように、Move値のツリーは、正直なところ、やりすぎです。applyMoves操作が示すように、任意のFoldableコンテナで十分です。これは、データ構造を走査し、各Moveについて、最初にファイルをコピーし、次にコピーが成功したことを確認し、最後に、成功した場合は、移動元のファイルを削除します。
これらの3つのステップで呼び出されるすべての操作は、base GHCインストールの一部であるさまざまなライブラリで定義されています。詳細に関心がある場合は、ソースコードリポジトリを参照してください。
構成
これで、すべてのレゴブロックから不純/純粋/不純のサンドイッチを構築できます。
movePhotos :: FilePath -> FilePath -> IO ()
movePhotos source destination = fmap fold $ runMaybeT $ do
sourceTree <- lift $ readTree source
photoTree <- MaybeT $ catMaybeTree <$> traverse readPhoto sourceTree
let destinationTree = calculateMoves $ moveTo destination photoTree
lift $ applyMoves destinationTree
最初に、readTree操作を使用してsourceTreeをロードします。これは、コードがdo記法で記述されており、コンテキストがMaybeT IO ()であるため、Tree FilePath FilePath値です。次に、readPhotoでsourceTreeを走査して、画像メタデータをロードします。これにより、次にcatMaybeTreeでフィルタリングするTree FilePath (Maybe PhotoFile)が生成されます。ここでも、do記法とモナド変換子の特性により、photoTreeはTree FilePath PhotoFile値になります。
コードのこれらの2行は、サンドイッチの最初の純粋でないステップです(はい、比喩が混ざっていることは承知しています)。
サンドイッチの純粋な部分は、純粋関数moveToとcalculateMovesの合成です。結果はTree FilePath Move値です。
サンドイッチの最後の純粋でないステップは、applyMovesの実行です。
実行
movePhotos操作は、source引数とdestination引数を受け取ります。理論的には、リッチクライアントまたはバックグラウンドプロセスから呼び出すことができますが、ここでは、コマンドラインプログラムから呼び出すだけです。main操作は、入力引数を解析し、movePhotosを呼び出す必要があります。
main :: IO ()
main = do
args <- getArgs
case args of
[source, destination] -> movePhotos source destination
_ -> putStrLn "Please provide source and destination directories as arguments."
プログラム引数の解析をもっと洗練させることもできますが、それはこの記事の主題ではないため、プログラムを動作させるために必要な最小限のコードのみを記述しました。
これで、プログラムをコンパイルして実行できます。
$ ./archpics "C:\Users\mark\Desktop\Test" "C:\Users\mark\Desktop\Test-Out"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2003-04\\2003-04-29 15.11.50.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2011-07\\2011-07-10 13.09.36.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-17 17.11.40.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-18 14.05.02.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-05\\2014-05-23 16.07.20.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-30 15.44.52.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-21 16.48.40.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2016-05\\2016-05-01 09.25.23.jpg"
Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2017-08\\2017-08-22 19.53.28.jpg"
これにより、期待どおりの移動先ディレクトリ構造が生成されます。
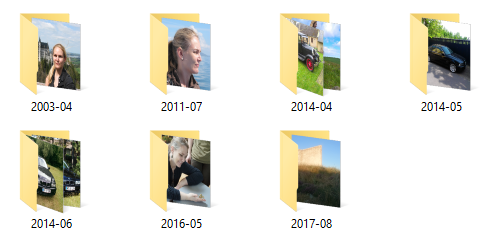
理論だけでなく、実際にも動作することがわかると、いつも嬉しいものです。
まとめ
関数型ソフトウェアアーキテクチャでは、純粋な関数が純粋でない操作を呼び出さないように、純粋なコードを純粋でないコードから分離します。多くの場合、これは、私が不純/純粋/不純のサンドイッチアーキテクチャと呼ぶもので実現できます。この例では、ファイルシステムをツリーとしてモデル化する方法を見てきました。これにより、純粋でないファイル操作を純粋なプログラムロジックから分離できます。
Haskell型システムは、アーキテクチャが確かに適切に関数型であることを意味する関数型インタラクションの法則を強制します。F#などの他の言語は、コンパイラを介してこの法則を強制しませんが、関数型プログラミングを行うことを妨げるものではありません。アーキテクチャが確かに関数型であることが検証されたので、これをF#に移植できます。